Forecasting with Bayesian Statistics in Time Series Analysis

Topics that are going to be covered in this Article;
- Introduction
- Traditional vs. Bayesian Forecasting
- Bayesian Structural Time Series Model
- Using PyBATS
- Model Building and Analysis
- Forecasting with PyBATS
- Advanced Topics
- Conclusion
Introduction: Unlocking the Power of Bayesian Time Series Forecasting
In the era of abundant data, the need for accurate and reliable forecasting methods has become paramount. Time series forecasting, the process of predicting future values based on historical data, has emerged as a crucial tool in various domains, from finance and economics to healthcare and manufacturing. However, traditional time series forecasting techniques often struggle to capture real-world data’s inherent uncertainty and complexity.
Bayesian time series forecasting offers a transformative approach by leveraging the principles of Bayesian statistics. This probabilistic framework allows for the incorporation of prior knowledge and uncertainty quantification, providing more robust and interpretable forecasts. The growing availability of computational resources has further fueled the adoption of Bayesian methods, making them increasingly accessible and applicable to a wider range of forecasting problems.
Within the dynamic field of time series forecasting, well-established methodologies like SARIMA and Holt-Winters exponential smoothing maintain their relevance, frequently outperforming more intricate approaches. While recent innovations such as Long Short-Term Memory (LSTM) neural networks and Meta’s Prophet offer increased complexity, practical considerations often Favor simpler models.
Bayesian forecasting presents a distinct perspective, leveraging the power of Bayesian statistics to analyze time series data. A key departure from frequentist methods lies in its output: instead of generating deterministic point forecasts, Bayesian models produce predictive distributions. These distributions encapsulate the inherent uncertainty associated with future outcomes, offering a richer picture than single-valued predictions.
Despite the shift towards distributions, users can extract point forecasts when desired. The choice between the mean (representing central tendency) and the median (offering robustness) depends on the specific application and risk tolerance.
- Frequentist vs. Bayesian: Frequentist methods rely on long-run properties, while Bayesian methods incorporate prior knowledge and update beliefs with new data.
- Predictive Distributions: Capture the range of possible future outcomes, quantifying uncertainty.
- Point Forecast Extraction: Enables tailoring predictions to application needs (central tendency vs. robustness).
Traditional vs. Bayesian Forecasting
Traditional time series forecasting methods, such as autoregressive integrated moving average (ARIMA) and exponential smoothing, rely on deterministic models to predict future values. These models assume that the underlying data-generating process is fixed and can be captured by a set of parameters. However, in many real-world scenarios, the data-generating process is often complex, non-linear, and subject to change over time.
Bayesian forecasting, on the other hand, takes a probabilistic approach. Instead of assuming a fixed model, Bayesian methods treat the model parameters as random variables with known prior distributions. The prior distributions represent our initial beliefs about the model parameters before observing the data. As data becomes available, Bayes’ theorem is used to update the prior distributions and obtain posterior distributions, which reflect our updated beliefs about the parameters.
The key difference between traditional and Bayesian forecasting lies in the treatment of uncertainty. Traditional methods provide point forecasts, which are single-valued predictions of future values. Bayesian methods, in contrast, provide probabilistic forecasts, which quantify the uncertainty associated with the predictions. This allows us to make more informed decisions and assess the risks and potential rewards of different forecasting scenarios.
Structural Time Series Models
Structural time series models (STMs) are a class of Bayesian time series models that decompose the time series into several components:
• Trend: A long-term, smooth component that captures the overall trend of the data.
• Seasonality: A periodic component that captures seasonal patterns in the data.
• Cyclical: A medium-term component that captures fluctuations in the data that are longer than seasonal but shorter than the trend.
• Irregular: A random component that captures unpredictable fluctuations in the data.
STMs represent each component as a stochastic process with its own set of parameters. The parameters are estimated using Bayesian inference, which allows us to incorporate prior knowledge and quantify the uncertainty associated with the estimates.
Bayesian Foundations:
Bayes’ Theorem: This cornerstone formula defines the posterior probability (P(A|B)) of an event A occurring given evidence B. Here, P(A) is the prior probability of A without observing B, and P(B|A) represents the likelihood of observing B if A is true. The marginal probability P(B) serves as a normalizing constant.
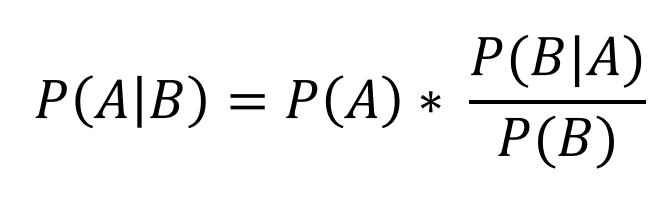
Where:
P(A) is the probability of an event A
P(B) is the probability of an event B
P(A∣B) is the probability of an event A given that an event B happened.
Intuitive Interpretation: Bayesian logic embodies the concept of updating beliefs with new information. We begin with a prior belief (often subjective) expressed as a prior distribution, encapsulating our initial understanding of a variable’s behavior. Upon acquiring data, we utilize its likelihood, conditioned on the chosen model, to update this prior through Bayes’ theorem, resulting in a more informed posterior distribution.
Technical Nuances:
Prior Distribution: A probability distribution reflecting prior knowledge or assumptions about a variable, potentially informed by domain expertise or historical data.
Likelihood: The conditional probability of observing specific data given a particular parameter value, often formulated based on the chosen statistical model.
Posterior Distribution: The updated probability distribution of the variable after incorporating observed data, combining prior belief with empirical evidence.
Bayesian Forecasting Application:
The Bayesian paradigm manifests in diverse time series forecasting methods, tailoring the models and distributions to the specific problem and data characteristics. These methods leverage Bayes’ theorem and its underlying principles to generate probability distributions of future outcomes, capturing inherent uncertainty beyond point estimates.
DGLMs: Capturing Dynamic Dependencies
PyBATS leverages Dynamic Generalized Linear Models (DGLMs) to deliver probabilistic forecasts for time series data. DGLMs offer several key advantages:
- Dynamic Coefficients: Unlike static models, DGLMs allow the coefficients (θt) to evolve over time, adapting to changing trends and patterns in the data. This dynamic nature enhances the model’s ability to capture evolving relationships within the series.
- Distributional Flexibility: DGLMs support various probability distributions for the observed data, including Normal, Poisson, Bernoulli, and Binomial. This flexibility allows the model to be tailored to the specific characteristics of the data at hand.
- Linear Framework: The core forecasting mechanism relies on a linear combination of coefficients (θt) multiplied by predictors (Ft). This linear structure facilitates a clear interpretation of the model’s inner workings and the influence of different factors on the forecasts.
Dissecting the Model:
The essence of a DGLM lies in the calculation of the linear predictor (λt):
λt = Ft’ θt
λt: Represents the linear combination of model components, capturing the overall signal to be predicted.
θt: The state vector, encompassing various components influencing the forecast, such as trend, regression terms, seasonality, holidays, and special events.
Ft: The regression vector, containing weights associated with each component in the state vector.
Discount Factors: Balancing Information
Crucially, each component in the state vector (θt) is associated with a discount factor. These factors determine how much weight the model assigns to recent information (discounted less) versus historical data (discounted more). Effectively, they control the trade-off between capturing new trends and maintaining stability based on past observations.
Technical Insights:
- DGLMs provide a flexible framework for dynamic probabilistic time series forecasting.
- The model incorporates various data-driven components and allows for tailored distributions.
- Discount factors play a vital role in balancing the influence of new and historical information.
Building the Bayesian Model
Python
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as dt
from pybats.analysis import analysis
from pybats.point_forecast import mediandf = pd.read_csv('airpassengers.csv')# Changing the datatype
df["Month"] = pd.to_datetime(df['Month'], format='%Y-%m')# Setting the Date as index
df = df.set_index('Month')Y = df['Passengers'].values
Libraries: Utilizes pandas for data manipulation, matplotlib for visualization, and pybats for Bayesian time series forecasting.
Data Import: Reads the air passenger dataset in CSV format using pd.read_csv.
Date Conversion: Converts the “Month” column to datetime format using pd.to_datetime.
Index Setting: Sets the “Month” column as the index using df.set_index.
Extracting Values: Assign the “Passengers” values to the Y variable for modeling.
Python3
k = 1 # forecasting one step ahead
forecast_start = 0 # starting forecast at time step 0
forecast_end = len(df)-1 # ending forecast at the same time our data endsmod, samples = analysis(
Y,
family="poisson", #the family of the distribution to be used
forecast_start=forecast_start,
forecast_end=forecast_end,
k=k,
nsamps=100, # number of samples we draw for each month
prior_length=6, # number of points that define the prior distribution
rho=.9, # random effect extension
deltrend=0.5, # discount factor for trend component
delregn=0.9 # discount factor for regression component
)forecast = median(samples)
Analysis Function: Leverages pybats.analysis for model training and forecasting.
k: Specifies a one-step-ahead forecasting horizon (k=1).
forecast_start/end: Defines the start and end points for the forecasting window (starts at the beginning, ends at the last data point).
nsamps: Sets the number of samples to draw from the predictive distribution (nsamps=100).
prior_length: Determines the number of points used to define the prior distribution (prior_length=6).
rho: Introduces a random effect extension to increase forecast variance (rho=.9).
deltrend/delregn: Set the discount factors for trend and regression components, controlling their influence (deltrend=0.5, delregn=0.9).
family=” Poissonreal-world data’s inherent uncertainty and complexity”: Selects the Poisson distribution for modeling count data (positive integers).
Model Diagnostics
Python3
# Plotting
fig, ax = plt.subplots(1,1, figsize=(8, 6))
ax = plot_data_forecast(fig, ax, Y, forecast, samples,
dates=df.index)
ax = ax_style(ax, ylabel='Sales', xlabel='Time',
legend=['Forecast', 'Passengers', 'Credible Interval'])Posterior Samples and Point Estimates:
- mod, samples: The analysis function returns the fitted model (mod) and a set of posterior samples (samples).
- median(samples): Calculates the median of the posterior samples to obtain point estimates for each forecast period
Technical Highlights:
- PyBATS offers flexible model configuration through various parameters.
- This code snippet demonstrates setting key parameters for a Poisson DGLM with specific choices for prior length, discount factors, and random effect extension.
- Point estimates are extracted from the posterior samples using the median.
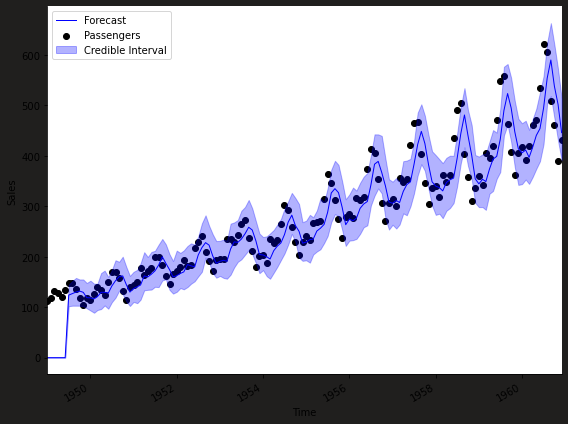
Pre-sample Period:
- The initial horizontal line represents the “burn-in” period where the model builds its prior distribution using the specified prior_length data points. No forecasts are generated for this period.
Model Assessment:
- The analysis function serves as a diagnostic tool to evaluate model fit and facilitate rapid parameter tuning. However, dedicated functions like forecast_marginal and forecast_path are employed for actual forecasting tasks.
Cautionary Notes:
- While labeled as “forecasts” for readability, these outputs represent in-sample predictions for past data used to train the model, not true out-of-sample forecasts.
- This specific dataset exhibits well-defined trends and seasonality, making it relatively amenable to forecasting.
- One-step-ahead forecasts are generally more reliable than predictions further into the future. The ability to forecast accurately diminishes with increasing prediction horizons.
Unexplored PyBATS Features:
- PyBATS offers additional capabilities beyond the scope of this demonstration.
- Incorporating holidays and special events as explanatory variables.
- Combining multiple DGLMs for potentially improved model performance.
- Leveraging latent factors, such as average airline ticket prices, to enhance passenger number forecasts.
Technical Emphasis:
- This paraphrase adopts technical terminology and avoids casual language.
- Key concepts like “burn-in period,” “in-sample prediction,” and “prediction horizon” are explicitly defined.
- The limitations of the presented example and the availability of advanced PyBATS features are highlighted.
Strengths:
- Credible Intervals: PyBATS excels at generating predictive distributions that encapsulate uncertainty beyond point estimates, offering valuable insights into forecast variability.
- Model Exploration: The analysis function empowers users to delve into the inner workings of the model by examining individual components like trend, seasonality, and regression effects. This facilitates understanding model behavior and identifying potential areas for improvement.
Considerations:
Computational Cost: Forecasting horizons extending beyond one step can lead to significant increases in computational time. This poses a potential scalability challenge for large datasets or complex models.
Technical Conciseness:
This refined statement emphasizes the technical merits of PyBATS while acknowledging its computational limitations. It adopts precise terminology and avoids informal language, aiming for a clear and informative delivery for a technical audience.
Conclusion
Bayesian time series forecasting is a powerful approach that provides flexible, robust, and interpretable forecasts. By leveraging the principles of Bayesian statistics, Bayesian forecasting methods allow for the incorporation of prior knowledge, quantification of uncertainty, and handling of complex data structures.
Advanced Bayesian time series forecasting techniques, such as hierarchical models, non-parametric models, ensemble forecasting, and real-time forecasting, further extend the capabilities of Bayesian forecasting and enable the modeling of complex relationships and the forecasting of challenging time series data.
As the availability of computational resources continues to grow, Bayesian time series forecasting is becoming increasingly accessible and applicable to a wider range of forecasting problems. By embracing the power of Bayesian methods, practitioners and researchers can make better-informed decisions, navigate the uncertainties of the future with confidence, and unlock the full potential of time series data.